Parallel Workers¶
In this chapter, we describe how Oríon can be run on multiple cores or computers for the same optimization experiments.
In most frameworks, a master-workers architecture is used. This implies that the master process must be instantiated either by the user or by a third party provider, which incurs a significant overhead for the users and third party dependencies – often requiring to have an internet connection.
Oríon has a different approach that nullify these issues: we don’t have a master process. Instead, the workers make decisions based on their shared common history stored in the database. The operations in the database are non-blocking, ensuring horizontal scalability for large search spaces.
We illustrate below the workflow for an hyperparameter optimization with a single worker, typically executed on a personal laptop.
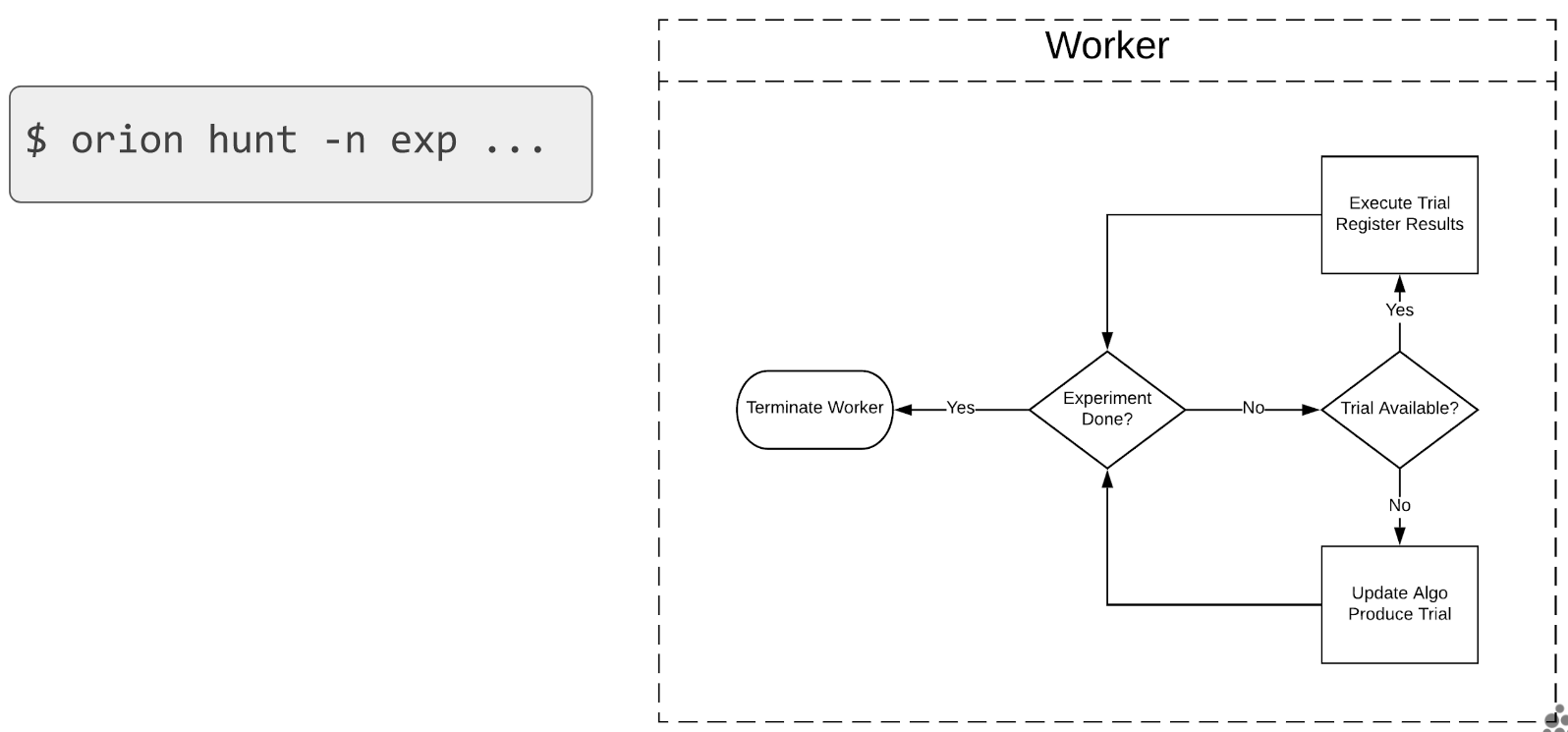
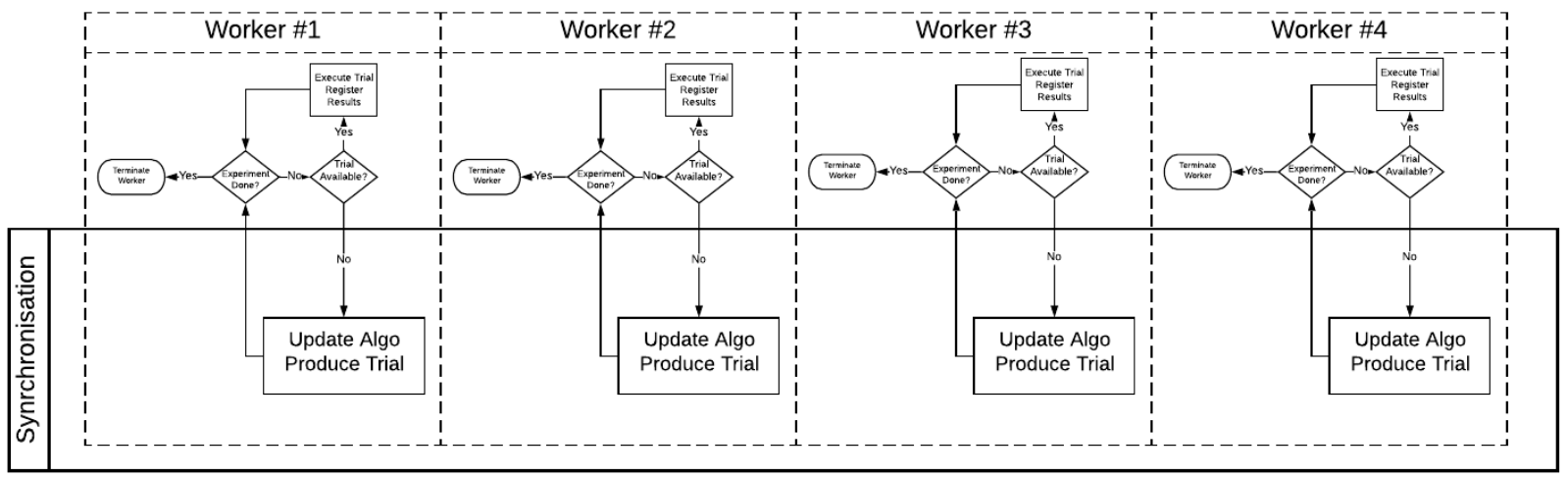
More workers can be invoked by simply running the $ orion hunt -n exp ... command multiple
times. Each call spawns a new worker for the given experiment. The workers’ workflow is unchanged
because the workers are synchronized during the creation of a new trial based on what other trials
were already completed by other workers.
Executor backends¶
It is also possible to execute multiple workers using the argument --n-workers in commandline
or experiment.workon(n_workers) using the python API. The workers will work together
using the same mechanisms explained above, but an
orion.executor.base.BaseExecutor backend will be used in addition
to spawn the workers and maintain them alive. The default backend is Joblib.
You can configure it
via a global or a local configuration file (executor_configuration)
or by passing it as an argument to orion.client.experiment.ExperimentClient.tmp_executor().
Joblib¶
Joblib is a lightweight library for task parallel execution in Python. We use the loky
backend of joblib by default to spawn workers on different processes.
The joblib backend is configured using parallel_backend().
See documentation at parallel_backend() for information on possible arguments.
Dask¶
It is possible to use dask with the joblib backend. Joblib can be configured to use Dask as explained here. For more control over Dask, you should prefer using Dask executor backend directly. The executor configuration is used to create the Dask Client. See Dask’s documentation here for more information on possible arguments.